 HOME
HOME 書き込む
書き込む
|
HOME |
|
|
書き込む |
| メソッド | 説明 |
|---|---|
| elt! | $ELT および $ELT{ETP} クラスで定義されているイテレーターで、入れものクラスの要素を順番に返します。 |
| copy | self をコピーして返します。$CONTAINER クラスで定義されています。 |
| has(e: ETP) | self が e を含めば true を返します。 |
| size | 要素の数を返します。 |
01: -- a simple typecase program 02: 03: class MAIN is 04: 05: main is 06: a:ARRAY{$STR}:=#(|1, 2.12, 3.14159d, "Hello", #INTI(1000000), 'c'|); -- 文字列に変換できる要素 6個からなる配列 a を定義 07: s:STR; -- .str が定義されていれば何でもこの配列に格納することができる。 08: loop 09: i:$STR:=a.elt!; -- a の要素を取り出して 10: typecase i -- データ型によって処理を振り分ける。 11: when INT then 12: s:="INT: "; 13: when FLT then 14: s:="FLT: "; 15: when FLTD then 16: s:="FLTD: "; 17: when INTI then 18: s:="INTI: "; 19: when STR then 20: s:="STR: "; 21: else 22: s:="Other: "; 23: end; 24: #OUT + "a[" + a.ind! +"] = " + s + i.str + "\n"; 25: end; 26: end; 27: end;
$ sacomp typecase.sa -o typecase $ ./typecase a[0] = INT: 1 a[1] = FLT: 2.12 a[2] = FLTD: 3.14159 a[3] = STR: Hello a[4] = INTI: 100000000 a[5] = Other: c
a0:ARRAY{INT}=#(|1,2,3|); -- a0[0]=1, a0[1]=2, a0[2]=3
a1:ARRAY{INT}=#(3); -- INT 3 個分のメモリー領域を確保した配列を生成
a2::=#ARRAY{INT}; -- INT 0 個分のメモリー領域を確保した配列を生成
また、他の $ELT{T} クラスから ARRAY{T} クラスのインスタンスを生成する create_from(e: $ELT{T}):SAME もあります。
| メソッド | 説明 |
|---|---|
| append | 配列を結合します。引数が1個から3個のものがあります。 |
| binary_search(e:T) | ソート済みの配列から e を探して、そのインデックスを返します。 |
| copy | self をコピーします。いろいろな引数をとるものがあります。 |
| count(e:T) | e の数を返します。 |
| has(e:T) | e があったら true を返します。 |
| remove(e:T) | e を取り除いた配列を返します。 |
| remove_duplicates | 重複を取り除いた配列を返します。 |
| reverse | 要素の順番を逆にした配列を返します。 |
| size | 要素の数を返します。 |
| sort | ソートします。 |
| str | 文字列に変換します。 |
| elt! | 要素を1つずつ取り出します。 |
| ind! | インデックスを1つずつ取り出します。 |
| set!(e:T) | 配列のはじめから代入していきます。 |
実は、Sather の関数は C 言語の関数と同じように引数を使って値を返すこともできるのですが、 TUP を使って複数の値を返すほうがバグが少なくなるでしょう。
例:tup.sa。 人物の属性を TUP{INT, STR, CHAR, INT} で表す。
01: -- a simple TUP program 02: 03: class MAIN is 04: 05: shared id:INT:=0; 06: make_person(name:STR, sex:CHAR, age:INT):TUP{INT, STR, CHAR, INT} is 07: id:= id+1; 08: return #(id, name, sex, age); 09: end; 10: 11: person_id(p:TUP{INT,STR,CHAR,INT}):INT is 12: return p.t1; 13: end; 14: 15: person_name(p:TUP{INT,STR,CHAR,INT}):STR is 16: return p.t2; 17: end; 18: 19: person_sex(p:TUP{INT,STR,CHAR,INT}):STR is 20: if p.t3 = 'm' then return "male"; 21: else return "female"; 22: end; 23: end; 24: 25: person_age(p:TUP{INT,STR,CHAR,INT}):INT is 26: return p.t4; 27: end; 28: 29: show_person(p:TUP{INT,STR,CHAR,INT}):STR is 30: return "ID: " + person_id(p).str + 31: "\nNAME: " + person_name(p) + 32: "\nSEX: " + person_sex(p) + 33: "\nAGE: " + person_age(p).str + "\n\n"; 34: end; 35: 36: main is 37: #OUT + "TUP test using person properties.\n\n"; 38: a:ARRAY{TUP{INT,STR,CHAR,INT}}:=#(|make_person("Jhon Smith", 'm', 50), make_person("Mary McCarthy", 'f', 25)|); 39: loop 40: #OUT + show_person(a.elt!); 41: end; 42: end; 43: end;
$ sacomp tup.sa -o tup $ ./tup TUP test using person properties. ID: 1 NAME: Jhon Smith SEX: male AGE: 50 ID: 2 NAME: Mary McCarthy SEX: female AGE: 25上の例は、本当は PERSON クラスを定義したほうがよいのでしょうが、TUP の例を示すため、強引に TUP{INT,STR,CHAR,INT} を使いました。
01: -- swc.sa: a simple words counts program written in sather 02: 03: class MAIN is 04: 05: const nonword_chars:STR:=" \t\n\r.,\"\\\`\':;?!()/-"; -- 両端にあるとき単語に含めない文字 06: 07: -- check if the character is a word character. 08: is_wordchar(c:CHAR):BOOL is 09: return ~nonword_chars.contains(c); -- 両端にあるとき単語に含めない文字でなければ true を返す。 10: end; 11: 12: -- truncating non_word characters from the head or tail of the word. 13: w_truncate(w:STR, headp:BOOL):STR is -- 単語の両端から単語に含めない文字列を削る。 14: idx,begin,num:INT; 15: num:=w.size-1; 16: if headp then 17: idx:=0; 18: begin:=1; 19: else 20: idx:=num; 21: begin:=0; 22: end; 23: if w.size=0 or is_wordchar(w.char(idx)) then 24: return w; 25: else 26: return w_truncate(w.substring(begin,num), headp); 27: end; 28: end; 29: 30: -- modifing the word to add to the hash table 31: w_modify(w:STR):STR is -- 両端を削った後小文字に変換 32: return w_truncate(w_truncate(w, false), true).lower; 33: end; 34: 35: -- making a word count hash table 36: make_hash(f:FILE):MAP{STR, INT} is -- (単語, 出現回数) のハッシュ表を作る。 37: hash::=#MAP{STR,INT}; 38: line,w:STR; 39: loop 40: until!(f.eof); 41: line:=f.get_str + " "; -- 最後に Space 文字を足さないと行の最後の単語が split! でかからない。 42: loop 43: w:=w_modify(line.split!(' ')); 44: if w.size > 0 then 45: if hash.has_ind(w) then 46: hash[w]:=hash[w]+1; 47: else 48: hash[w]:=1; 49: end; 50: end; 51: end; 52: end; 53: return hash; 54: end; 55: 56: -- getting the sorted array of the keys of the hash table 57: get_sorted_key(wc:MAP{STR,INT}):ARRAY{STR} is -- ハッシュ表のキー(単語)を配列に書き出しソートして返す。 58: a:ARRAY{STR}:=#(wc.size); -- この操作は出現回数をアルファベット順にソートして表示するために行う。 59: loop -- オンラインドキュメントに載っているinds というメソッドは実際は無い。 60: a.set!(wc.ind!); 61: end; 62: return a.sort; 63: end; 64: 65: -- showing the result of word count, sorted by word. 66: show_resul(wc:MAP{STR,INT}) is -- 結果の表示 67: w:STR; 68: loop 69: w:=get_sorted_key(wc).elt!; 70: #OUT + w + "\t" + wc[w] + "\n"; 71: end; 72: end; 73: 74: -- practical main function, counting word in a file 75: count_words(filename:STR) is -- 実質的なメイン関数 76: f::=FILE::open_for_read(filename); 77: if f.error then 78: #ERR + "Cannot open " + filename + "\n"; 79: else 80: show_resul(make_hash(f)); -- ファイルが開けたらハッシュ表を作ってそれを表示する。 81: f.close; 82: end; 83: end; 84: 85: main(av: ARRAY{STR}) is 86: if (av.size = 2) then 87: count_words(av[1]); 88: else 89: #ERR + "Usage: scw FILENAME\n"; 90: end; 91: end; 92: end; -- MAIN
例として、幅優先探索 (BFS) のプログラムを示します。BFS ではキューの先頭から探索の途中結果を取り出して、そこから一段深く探索を行い、 その結果をキューの末尾に加えていくことで探索を行います。下のコード (bfs.sa) は図 1 に示すグラフのスタートからゴールまでの最短経路を返します。
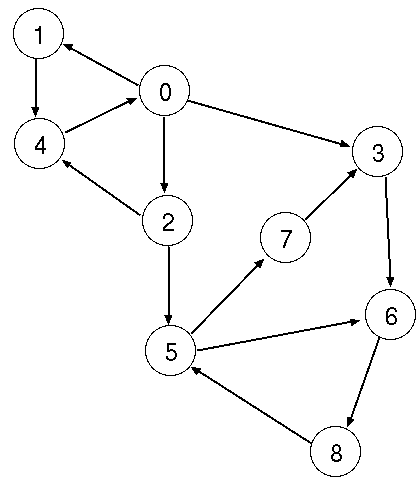
図1: bfs.sa で使用したグラフ。
01: -- bfs.sa: a simple breadth fast search 02: 03: class MAIN is 04: 05: const gr:ARRAY{ARRAY{INT}}:=| |1,2,3|, |4|, |4,5|, |6|, |0|, |6,7|, |8|, |3|, |5| |; -- 図1のグラフを ARRAY{ARRAY{INT}} で表現したもの。 06: attr goal:INT; -- ゴール 07: attr queue:LIST{LIST{INT}}; -- 探索待ち行列。LIST{LIST{INT}} で表現。 08: 09: bfs is -- 幅優先探索を行うメソッド。 10: if queue.size=0 then 11: #OUT + "Can not find the path\n"; -- 待ち行列が無くなったらその旨を表示して、 12: UNIX::exit(1); -- 終了。 13: end; 14: path:LIST{INT}:=queue[0]; -- 待ち行列の最初の要素(経路)を取り出す。 15: queue.remove_index(0); -- 待ち行列の最初の要素を削除 16: next_nodes:ARRAY{INT}:=gr[path[path.size-1]]; -- 今いる場所 (path[path.size-1]) から行ける場所の配列を取得 17: node:INT; 18: loop 19: node:=next_nodes.elt!; -- 次に行ける場所をを順番に調べる。 20: if node=goal then -- もしゴールだったら 21: #OUT + "found: " + path.append(goal) + "\n"; -- スタートからゴールまでの経路を示して終了。 22: UNIX::exit(0); 23: elsif ~path.has(node) then -- もし、まだ訪れていない場所だったら、 24: queue.append(path.append(node)); -- その場所を今までの経路 (path) の末尾に付け加えて、それを待ち行列の末尾に加える。 25: end; 26: end; 27: bfs; -- 再帰的に bfs を呼び出す。 28: end; 29: 30: main(av:ARRAY{STR}) is 31: if av.size=3 then -- 引数が2個だったら、 32: goal:=av[2].cursor.get_int; -- 2番目の引数をゴールにセット 33: queue:=#; -- 待ち行列を初期化 34: queue.append(#(|av[1].cursor.get_int|)); -- 待ち行列にスタート地点を追加 35: bfs; -- 幅優先探索を実行 36: else 37: #ERR + "Usage: bfs START GOAL\n"; 38: end; 39: end; 40: end;
$ sacomp bfs.sa -o bfs
$ ./bfs 1 7 -- 1 から 7 までの経路を探索
found: {1,4,0,2,5,7}
スタックを使ったプログラムの定番として、逆ポーランド語法の電卓を作ってみました。 逆ポーランド語法の電卓は括弧を使わないで複雑な計算ができるので慣れれば便利です。 ここでは簡単のため四則演算だけを実装します。
01: -- calc.sa: a simple reverse polish calculator 02: 03: class MAIN is 04: 05: const op:STR:="+-*/"; 06: const re:REGEXP:=REGEXP::regexp("^[+\\-]?[0-9]+\\.?[0-9]*$", false); -- 数字の正規表現 07: shared stack:FLIST{FLTD}:=FLIST{FLTD}::create; -- FLTD を積むスタック 08: 09: operatorp(word:STR):BOOL is 10: return (word.size = 1 and op.contains(word.char(0))); 11: end; 12: 13: numberp(word:STR):BOOL is 14: return re.match(word); 15: end; 16: 17: calculate(word:STR) is -- スタックから上の2つを取り出して、 18: c:CHAR:=word.char(0); 19: f1,f2, fr:FLTD; 20: f2:=stack.pop; 21: f1:=stack.pop; 22: case c -- それらの数の四則演算を行い、 23: when '+' then fr := f1+f2; 24: when '-' then fr := f1-f2; 25: when '*' then fr := f1*f2; 26: when '/' then fr := f1/f2; 27: else #ERR + "The operature is not supoorted.\n"; 28: end; 29: stack:=stack.push(fr); -- 結果をスタックに積む 30: end; 31: 32: push_to_stack(word:STR) is 33: stack:=stack.push(word.cursor.get_fltd); 34: end; 35: 36: main(av: ARRAY{STR}) is 37: line, word:STR; 38: loop 39: #OUT + "> "; 40: if ~void(stack) then 41: #OUT + stack[0] + " "; 42: end; 43: line:=#IN.get_str; 44: if line.size = 0 then break!; end; -- 何も入力しないでリターンしたときはプログラムを終了 45: line := line + " "; 46: loop 47: word := line.split!(' '); 48: word := word.head(word.size-1); 49: if operatorp(word) then calculate(word); 50: elsif numberp(word) then push_to_stack(word); 51: end; 52: end; 53: end; 54: end; 55: end;
$ sacomp calc.sa -o calc $ ./calc > 1 8 + 3.7 0.7 - / -- (1 + 8) / (3.7 - 0.7) > 3 0.01 * -- 前の計算の結果に続けて計算ができる。 > 0.03
| クラス | 説明 |
|---|---|
| ARRAY2{} | 2次元配列。 |
| ARRAY3{} | 3次元配列。 |
| BAG{} | 袋、要素を順番付けずに格納。同じ要素を複数格納できる。 |
| QUEUE{} | 待ち行列。実は bfs.sa はこのクラスを使ったほうがすっきり書ける。 |
| STACK{} | スタック。実は calc.sa はこのクラスを使ったほうがすっきり書ける。 |
| SET{} | 集合。union や intesection などの集合用の演算ができる。 |
|
HOME |
|
|
書き込む |