 HOME
HOME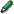 書き込む
書き込む
|
HOME |
書き込む |
例えば、[1,2,3] というリスト図1のような構造体(コンスセル)の列への最初のポインターとして実装できます。 これに、0 を Cons すると 0 のコンスセルを先頭に付け足すだけで新しいリスト [0,1,2,3] が生成したと して取り扱うことが出来ます。 つまり、コンスセルの先頭へのポインターをリストとすると、新しいリストが少ない操作と資源で作られることに なります。 ただし、すでに存在するリストの要素を削除したり、書き直したりする場合は全てのリストを新しく 作る必要があります。また、リストを走査するには O(n) の計算時間がかかります。 従って、参照を頻繁に行うプログラムではデータをリストとして表すのは速度的に不利です。
[図1]
例:三角関数の表を作りそれを利用して値を返す。
01: -- using Array 02: -- 03: module Main where 04: 05: import Array 06: 07: sin_cos :: Array Int Double -> Array Int Double -> IO() 08: sin_cos table_sin table_cos = do putStrLn "give sin/cos (angle)" 09: str <- getLine 10: if str /= "" 11: then do let w = words str 12: n = read (w !! 1) 13: table = if (w !! 0) == "sin" then table_sin else table_cos 14: putStrLn $ str ++ " = " ++ show (table ! n) 15: sin_cos table_sin table_cos 16: else return () 17: 18: main :: IO() 19: main = sin_cos ar_sin ar_cos 20: where ar_sin = listArray (0,360) [sin x | x <- [0..360]] 21: ar_cos = listArray (0,360) [cos x | x <- [0..360]] 22: 23:
D:\doc\05-04\hs>runhugs ar.hs give sin/cos (angle) sin 3 sin 3 = 0.141120008059867 give sin/cos (angle) cos 120 cos 120 = 0.814180970526562 give sin/cos (angle) cos 299 cos 299 = -0.853204385517229 give sin/cos (angle) D:\doc\05-04\hs>
| emptyFM | 新たに FiniteMap を生成します。 例: emptyFM :: FiniteMap Int Double |
| addToFM fm key val | FiniteMap fm に key val の要素を追加します。 |
| delFromFM fm key | FiniteMap fm から key の要素を削除します。 |
| elemFM key fm | key が FiniteMap fm の要素か調べます。 |
| lookupFM fm key | FiniteMap fm の要素のうち key を持つものの val をもしあれば返します。 |
| listToFM alist | 連想リスト alist を FiniteMap にします。 |
| fmToList fm | FiniteMap fm を連想リストにします。 |
例として、ファイルの単語の出現回数を調べるプログラムを示します。
[code 1]
01: --- count words occurence 02: --- 03: module Main where 04: import Data.FiniteMap 05: import System 06: import Char 07: import List 08: 09: count_words :: (FiniteMap String Int) -> [String] -> [(String, Int)] 10: count_words fm [] = fmToList fm 11: count_words fm (w:ws) = case lookupFM fm w of 12: Nothing -> count_words (addToFM fm w 1) ws 13: Just n -> count_words (updateFM fm w (1+n)) ws 14: where updateFM m k v = addToFM (delFromFM m k) k v 15: 16: conv_char :: Char -> Char 17: conv_char c = if isAlpha c 18: then toLower c 19: else if (isDigit c || isSpace c || c == '_') 20: then c 21: else ' ' 22: 23: main :: IO() 24: main = do av <- getArgs 25: str <- readFile (av !! 0) 26: mapM_ print $ sortBy (compare . fst) 27: $ count_words (emptyFM :: FiniteMap String Int) (words $ map conv_char str)
| 関数名 | 型 | 説明 |
|---|---|---|
| newIORef | a -> IO (IORef a) | 値 a を持つ新しい IORef を作ります。 |
| readIORef | IORef a -> IO a | IORef から値を読みます。 |
| writeIORef | IORef a -> a -> IO() | IORef に値を書き出します。 |
| modifyIORef | IORef a -> (a -> a) -> IO () | IORef の値を更新します。 |
| 関数名 | 型 | 説明 |
|---|---|---|
| newArray | (MArray a e m, Ix i) => (i, i) -> e -> m (a i e) | 値 e を持つ新しい配列を作成します。 例: インデックスが 0--99 で、値が 0.0 の Array を作成 newArray (0,99) 0.0 :: IO (IOUArray Int Double) |
| newListArray | (MArray a e m, Ix i) => (i, i) -> [e] -> m (a i e) | リストの値を持つ Array を作成 例:0.0, 0.1 ..... 9.9 の値を持つ Array newListArray (0,99) [0.0,0.1..9.9] |
| readArray | (MArray a e m, Ix i) => a i e -> i -> m e | Array から値を読む。 |
| writeArray | (MArray a e m, Ix i) => a i e -> i -> e -> m () | Array に値を書く。 |
01: ------------------------------------------------ 02: --- test code for Array.IO 03: --- simulation of diffusion 04: --- by T.Shido (shido_takafumi@ybb.ne.jp) 05: ------------------------------------------------ 06: 07: import Data.Array.IO 08: import System 09: 10: diffuse :: String -> Int -> IO() 11: diffuse fout m = do state <- newArray (0,199) 0.0 :: IO (IOUArray Int Double) 12: writeArray state 99 100.0 13: diff <- newArray (0,199) 0.0 :: IO (IOUArray Int Double) 14: rep state diff 0 m 15: where rep state diff i n | i==n = present state 0 "# diffusion:\n#cell, density\n" 16: | otherwise = do cal_diff state diff 1 17: up_state state diff 0 18: rep state diff (1+i) n 19: cal_diff state diff i | i == 199 = return () 20: | otherwise = do de <- readArray state i 21: if de /= 0.0 22: then do d0 <- readArray diff i 23: dsub1 <- readArray diff (i-1) 24: dadd1 <- readArray diff (i+1) 25: writeArray diff i (d0 - de*0.1) 26: writeArray diff (i-1) (dsub1 + de*0.05) 27: writeArray diff (i+1) (dadd1 + de*0.05) 28: cal_diff state diff (i+1) 29: else cal_diff state diff (i+1) 30: up_state state diff i | i==200 = return () 31: | otherwise = do d <- readArray diff i 32: if d /= 0.0 33: then do s <- readArray state i 34: writeArray state i (s+d) 35: writeArray diff i 0.0 36: up_state state diff (i+1) 37: else up_state state diff (i+1) 38: present state i acc | i==200 = writeFile fout acc 39: | otherwise = do x <-readArray state i 40: present state (i+1) (acc ++ show i ++ " " ++ show x ++ "\n") 41: 42: main = do av <-getArgs 43: diffuse (head av) (read (av !! 1)) 44:二次元配列の場合
[code 3]
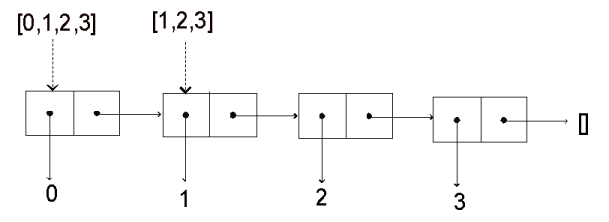
01: ------------------------------------------------ 02: --- test code for Array.IO 03: --- simulation of diffusion, 2D 04: --- by T.Shido (shido_takafumi@ybb.ne.jp) 05: ------------------------------------------------ 06: 07: import Data.Array.IO 08: import System 09: 10: -- 2 dimentinal diffusion 11: diffuse2d :: String -> Int -> IO() 12: diffuse2d fout m = do state <- newArray ((0,0), (49,49)) 0.0 :: IO (IOUArray (Int, Int) Double) 13: writeArray state (24,24) 100.0 14: diff <- newArray ((0,0), (49,49)) 0.0 :: IO (IOUArray (Int, Int) Double) 15: rep state diff 0 m 16: where rep state diff i n | i==n = present state 0 0 "# deffusion:\n#cell x, cell y, density\n" 17: | otherwise = do cal_diff state diff 1 1 18: up_state state diff 0 0 19: rep state diff (1+i) n 20: cal_diff state diff i j | i == 49 = return () 21: | j == 49 = cal_diff state diff (i+1) 1 22: | otherwise = do s0 <- readArray state (i, j) 23: if s0 > 0 24: then do d0 <- readArray diff (i, j) 25: d_up <- readArray diff ((i-1), j) 26: d_down <- readArray diff ((i+1), j) 27: d_left <- readArray diff (i, (j-1)) 28: d_right <- readArray diff (i, (j+1)) 29: writeArray diff (i, j) (d0 - s0*0.1) 30: writeArray diff ((i-1),j) (d_up + s0*0.025) 31: writeArray diff ((i+1),j) (d_down + s0*0.025) 32: writeArray diff (i,(j-1)) (d_left + s0*0.025) 33: writeArray diff (i,(j+1)) (d_right + s0*0.025) 34: cal_diff state diff i (j+1) 35: else cal_diff state diff i (j+1) 36: up_state state diff i j | i == 50 = return () 37: | j == 50 = up_state state diff (i+1) 0 38: | otherwise = do d <- readArray diff (i, j) 39: if d /= 0 40: then do s <- readArray state (i, j) 41: writeArray state (i, j) (s+d) 42: writeArray diff (i, j) 0.0 43: up_state state diff i (j+1) 44: else up_state state diff i (j+1) 45: 46: present state i j acc | i==50 = writeFile fout acc 47: | j==50 = present state (i+1) 0 (acc ++ "\n") 48: | otherwise = do x <-readArray state (i, j) 49: present state i (j+1) 50: (acc ++ show i ++ " " ++ show j ++ " " ++ show x ++ "\n") 51: 52: main = do av <-getArgs 53: diffuse2d (head av) (read (av !! 1)) 54:実行例: 図2に [code 2] を実行した結果を示します。キャプションは繰り返し回数です。 一方、図3に [code 3] を実行した結果を示します。
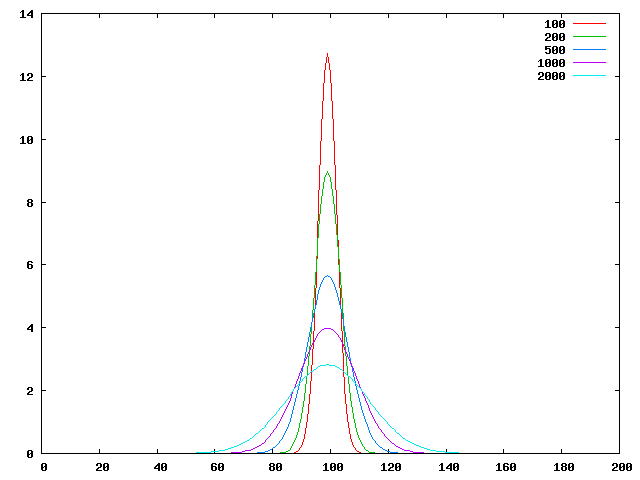
| 関数名 | 型 | 説明 |
|---|---|---|
| new | (key -> key -> Bool) -> (key -> Int32) -> IO (HashTable key val) | 新しいハッシュ表を作る。 最初の引数は key を比較する関数、2番目の引数は key を Int32 に変換する関数です。Int 用の hashInt、文字列用の hashString があります。 |
| insert | HashTable key val -> key -> val -> IO () | key, val をハッシュ表に追加する。 |
| delete | HashTable key val -> key -> IO () | key をハッシュ表から削除します。 |
| lookup | HashTable key val -> key -> IO (Maybe val) | key をハッシュ表から探し、見つかったら val を返します。 |
| update | HashTable key val -> key -> val -> IO Bool | ハッシュ表を key val で更新します。 |
| fromList | Eq key => (key -> Int32) -> [(key, val)] -> IO (HashTable key val) | リストからハッシュ表を作成します。 |
| toList | HashTable key val -> IO [(key, val)] | ハッシュ表をリストに変換します。 |
[code 4] にハッシュ表を使ってファイル中の単語の出現回数を数えるプログラムを示します。
[code 4]
01: --- count words 02: module Main where 03: 04: import Data.HashTable 05: import System 06: import Char 07: import List 08: 09: regword :: (HashTable String Int) -> [String] -> IO() 10: regword _ [] = return () 11: regword h (w:ws) = do cnt <- Data.HashTable.lookup h w 12: case cnt of 13: Nothing -> update h w 1 14: Just n -> update h w (1+n) 15: regword h ws 16: 17: conv_char c = if isAlpha c 18: then toLower c 19: else if (isDigit c || isSpace c || c == '_') 20: then c 21: else ' ' 22: 23: main = do av <- getArgs 24: contents <- readFile (head av) 25: h <- new (==) hashString :: IO (HashTable String Int) 26: regword h (words $ map conv_char contents) 27: al <- toList h 28: mapM_ print $ sortBy (compare . fst) al
|
HOME |
書き込む |